
This time we’ll have a look at some techniques for automatically generating music — or rather, to be more accurate, melodies. Since we’ve deduced that a musical scale is a mathematical structure in which it’s possible to perform all the standard operations, we have quite a lot of freedom when it comes to the choice of a suitable formalism. We’ll also make some simplifications to make the job easier: namely that our melodies consists of a single list of notes where all notes are assumed to be of equal importance, e.g. played in the same timbre and tempo. This means that the resulting melodies won’t be that pleasing to the ear, but there’s of course nothing that stops us from using one of these melodies as a building block in a larger musical composition. I suppose that we still need musicians for something!
Lindenmayer systems
A Lindermayer system, or an L-system, is a formal grammar quite similar to a context-free grammar. The goal is to rewrite a starting string, the axiom, by applying as many rules as possible. A rule is simply an if-then statement of the form: if the token is 
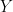

Where 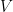
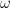

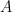



So the strings that will be produced are: 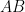
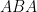
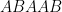
We are free to interpret the structure in an L-system in any way we see fit. For example, we could interpret
— draw forward.
— turn right.
— turn left.
— push the current point on the stack.
— pop an entry from the stack.
But since we’re working with scales, and not images, we have to reinterpret these commands. I propose the following:
Hence we’re going to use L-systems that produce strings in this format. From such a string it’s then possible to extract a melody. For example, the string 

We’ll return to this later. For now, let’s concentrate on implementing L-systems in Logtalk. This can be done in a large number of ways, but once we’ve chosen a suitable representation everything else will more or less follow automatically. Every L-system will be represented by an axiom and a set of production rules for both variables and constants. Since the production rules take symbols as argument and produces strings/lists, DCG’s are a fine choice. For the moment we can ignore everything else and just stipulate what an L-system is.
:- protocol(l_system).
:- public(rule//1).
:- public(axiom/1).
:- end_protocol.
:- object(algae,
implements(l_system)).
axiom([a]).
rule(a) --> [a,b].
rule(b) --> [a].
:- end_object.
Then we’ll need a predicate that takes a string as input and applies all applicable production rules. Since the rules themselves are written in DCG notation, it’s easiest to continue with this trend. The predicate will take a string and an L-system as input, and iteratively apply the rules for the elements in the string.
next([], _) --> [].
next([X|Xs], L) -->
L::rule(X),
next(Xs, L).
And all that remains is a predicate that calls 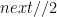
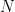
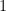
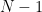
generation(1, L, X) :-
L::axiom(X).
generation(N, L, X) :-
N > 1,
N1 is N - 1,
generation(N1, L, Y),
phrase(next(Y, L), X, []).
This is almost too easy! For reference, let’s also implement an L-system that makes use of the Logo commands previously discussed.
:- object(koch_curve,
implements(l_system)).
axiom([f]).
rule(-) --> [-].
rule(+) --> [+].
rule(f) --> [f,+,f,-,f,-,f,+,f].
:- end_object.
This structure is known as a Koch curve, and when interpreted as drawing commands it looks like:

Now we’ll need a predicate that transforms a list of commands into a list of notes. It’ll need 4 input arguments:
— the list of commands.
— the scale that the notes shall be generated according to.
— the stack.
And one single output argument:
— the resulting list of notes.
It’s not that hard to implement since it only consists of a case-analysis of the command list. For example, if the command list is empty then the list of notes is empty. If the command is
transform([], _, _, _, []).
transform([f|Cs], Scale, N, S, [N|Ns]) :-
transform(Cs, Scale, N, S, Ns).
transform([-|Cs], Scale, N, S, Ns) :-
Scale::lower(N, N1),
transform(Cs, Scale, N1, S, Ns).
transform([+|Cs], Scale, N, S, Ns) :-
Scale::raise(N, N1),
transform(Cs, Scale, N1, S, Ns).
transform([s|Cs], Scale, N, S, Ns) :-
transform(Cs, Scale, N, [N|S], Ns).
transform([r|Cs], Scale, _, [N|S], Ns) :-
transform(Cs, Scale, N, S, Ns).
Putting everything together
We can now generate command strings from L-systems and convert these into notes in a given scale. What remains is to convert the notes into frequencies with a specific duration. These can then be converted into samples and be written to a WAV file.
generate_notes(L, I, Scale, Notes, Number_Of_Samples) :-
l_systems::generation(I, L, X),
Scale::nth(0, Tonic),
l_systems::transform(X, Scale, Tonic, [], Notes0),
findall(F-0.2,
(list::member(Note, Notes0),
Scale::frequency(Note, F)),
Notes),
length(Notes, Length),
synthesizer::sample_rate(SR),
Number_Of_Samples is Length*(SR/5).
The value 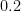
This is the curve depicted earlier. To be frank it sounds kind of dreadful, but fortunately the other samples are somewhat more interesting. Next up is the dragon curve!

I think it sounds much better than the Koch curve, but that might be due to the fact that I view my creations with rose-tinted eyes; unable to see the unholy abomination that is their true form. Let’s have a look at the Hilbert curve.

Catchy! The last L-system is a fractal plant.

I think the results are quite interesting, and this is only the tip of the iceberg since it’s possible to create any kind of L-system and interpret it as a melody. The whole set is available at Soundcloud.
I initially intended to include a section in which I created a Prolog interpreter that for each refutation also produced a melody, but the time is already running out. It’s not impossible that I’ll return to the subject at a later date however!
Source code
The source code is available at https://gist.github.com/1034067.
![[-32768, 32767]](https://s0.wp.com/latex.php?latex=%5B-32768%2C+32767%5D&bg=FFFFFF&fg=000&s=0&c=20201002) . It is perhaps also instructive to see a visual representation of the samples. Here’s the results:
. It is perhaps also instructive to see a visual representation of the samples. Here’s the results:
 , and for every new frequency add
, and for every new frequency add 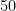 . This would result in a scale where the difference between any two adjacent frequencies is constant, or in other words linear. With
. This would result in a scale where the difference between any two adjacent frequencies is constant, or in other words linear. With 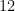 frequencies we would obtain:
frequencies we would obtain: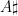 ,
, 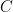 ,
, 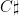 ,
,  ,
, 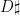 ,
, 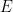 ,
, 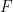 ,
,  ,
, 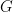 ,
,  , where the notes with funny looking sharp signs correspond to the small, black keys on a piano (so-called “accidentals”). For simplicity we’ll use the numeric notation though. The next question is how this scale sounds when it is played in succession.
, where the notes with funny looking sharp signs correspond to the small, black keys on a piano (so-called “accidentals”). For simplicity we’ll use the numeric notation though. The next question is how this scale sounds when it is played in succession.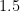 , but where the distance between the second and third frequency is
, but where the distance between the second and third frequency is 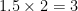 .
. , where
, where  and
and  are constants. For
are constants. For 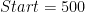 and
and 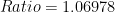 we get the scale:
we get the scale: ,
, 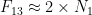 and so on. It’s not too hard to derive such a constant. Let
and so on. It’s not too hard to derive such a constant. Let  be the constant. Then
be the constant. Then 

 . Hence the general formula is
. Hence the general formula is 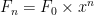
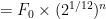
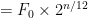 .
. as the unit element, which means that it’s quite pleasant to work with. The basic operations that we want to perform are:
as the unit element, which means that it’s quite pleasant to work with. The basic operations that we want to perform are: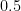 seconds and the sample rate is
seconds and the sample rate is  the number of samples is
the number of samples is 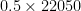
 . The wave will be generated with a loop from
. The wave will be generated with a loop from 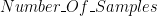 where the following operations are performed on each sample:
where the following operations are performed on each sample: , where
, where ![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=FFFFFF&fg=000&s=0&c=20201002) .
.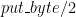 , which is not sufficient since it only works for single byte, signed integers. The good news is that we can get it to do what we want with some low-level bit-fiddling. Here’s the operations that we’ll need in order to produce a fully functional WAV file:
, which is not sufficient since it only works for single byte, signed integers. The good news is that we can get it to do what we want with some low-level bit-fiddling. Here’s the operations that we’ll need in order to produce a fully functional WAV file: , that has the format:
, that has the format: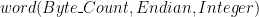
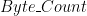 is either
is either 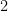 or
or 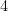 ,
, 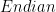 is either
is either  or
or 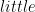 , and
, and 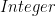 is a positive or negative integer. So to represent the number
is a positive or negative integer. So to represent the number 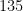 in the little endian format we would use:
in the little endian format we would use:
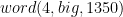
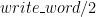 that writes a word to a stream. Let’s focus on 2 byte integers for the moment. A first attempt might look like:
that writes a word to a stream. Let’s focus on 2 byte integers for the moment. A first attempt might look like:![[word(4, big, 0x52494646), ...]](https://s0.wp.com/latex.php?latex=%5Bword%284%2C+big%2C+0x52494646%29%2C+...%5D&bg=FFFFFF&fg=000&s=0&c=20201002) . The format chunk follows the same basic structure:
. The format chunk follows the same basic structure: