
Introduction
Meta-programming is part of the folklore in Prolog, and is in general a rather old concept with roots tracing back to at least the 50’s. To give a definition that captures all the relevant concepts is outside the scope of this introductory text, but I shall at least provide some pointers that’ll be useful later on. Programs are useful in many different domains. We might be working with numbers, with graphs, with lists or with any other data structure. What happens when the domain is another programming language? Well, nothing, really, from the computer’s point of view there’s no difference between this scenario and the former. But conceptually speaking we’re writing programs that are themselves working with programs. Hence the word “meta” in meta-programming. A compiler or interpreter is by this definition a meta-program. But in logic programming we’re usually referring to something more specific when we’re talking about meta-programming, namely programs that takes other logic programs as data. Since Prolog is a homoiconic language there’s also nothing that stops us from writing programs that takes other Prolog programs as data, but even though there’s a subtle distinction between this and the former scenario they are often referred to as one and the same. So, to summarize, when we’re talking about meta-programs in logic programming we’re quite often referring to Prolog programs that uses logic programs as data.
The road map for this post is to see some examples of meta-interpreters in Prolog. Then we’re going to use the interpreters to aid program development with a technique known as algorithmic debugging. But enough talk, let’s do this!
Meta-interpreters
There’s still ample room for confusion regarding the word “meta” in meta-interpreter. I shall use the word whenever I refer to an interpreter for a logic programming language, even though this is not factually correct since one usually demands that the object language and the meta language are one and the same. That is: we write an interpreter for Prolog in Prolog. There are good reasons for not doing this. Prolog is a large and unwieldy language with many impure features such as cut, IO, assert/retract and so on, and when we’re working with meta-interpreters we’re often only interested in a small, declarative part of the language. Hence we shall restrict our focus to a programming language akin to pure Prolog which is basically just a set of Horn clauses/rules.
Even though we still haven’t decided the syntax for the object language we know that we must represent at least two things: facts and rules. Since a fact 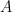



![rule(A, [B_1, ..., B_n])](https://s0.wp.com/latex.php?latex=rule%28A%2C+%5BB_1%2C+...%2C+B_n%5D%29&bg=FFFFFF&fg=000&s=0&c=20201002)
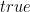
As an example, here’s how we would write 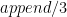
rule(append([], Ys, Ys), []). rule(append([X|Xs], Ys, [X|Zs]),[append(Xs, Ys, Zs)]).
Simple, but not exactly pleasing to the eye. Fortunately it’s easy to add some syntactic sugar with the help of Prolog’s term expansion mechanism. Instead of directly using 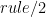
append([], Ys, Ys) :- true.
append([X|Xs], Ys, [X|Zs]) :-
append(Xs, Ys, Zs).
And then define a suitable expansion object so that we end up with a set of 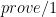
As mentioned the interpreter takes a list of goals as argument. This means that there’s a base case and a recursive case. In the base case of the empty list we are done. In the recursive case we have a list of the form ![[G|Gs]](https://s0.wp.com/latex.php?latex=%5BG%7CGs%5D&bg=FFFFFF&fg=000&s=0&c=20201002)
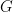

![([B_1, ..., B_n|Gs]) \theta](https://s0.wp.com/latex.php?latex=%28%5BB_1%2C+...%2C+B_n%7CGs%5D%29+%5Ctheta&bg=FFFFFF&fg=000&s=0&c=20201002)
%Initialize the goal list with G. prove(G) :- prove1([G]). prove1([]). prove1([G|Gs]) :- rule(G, B), prove1(B), prove1(Gs).
This is a prime example of declarative programming. We’ve only described what it means for a conjunction of goals to be provable and left the rest to the Prolog system. If you’re unsure why or how the interpreter works I urge you to try it for yourself.
Extensions
To prove that I wasn’t lying before I shall illustrate some neat extensions to the bare-bone interpreter. Strictly speaking we don’t really need anything else since the language is already Turing complete. It’s e.g. trivial to define predicates that define and operate on the natural numbers. For example:
nat(zero) :- true. nat(s(X)) :- nat(X). add(zero, Y, Y) :- true. add(s(X), Y, s(Z)) :- add(X, Y, Z).
But since these operations can be implemented much more efficiently on any practical machine it’s better to borrow the functionality. Hence we shall define a set of built-in predicates that are proved by simply executing them. The easiest way is to add a
rule(rule(A, B), []) :-
rule(A, B).
rule((X is Y), []) :-
X is Y.
Why the first clause? So that we can facilitate meta-programming and use
prove(G) :-
prove1([G]).
prove1([]) :- true.
prove1([G|Gs]) :-
rule(G, B),
prove1(B),
prove1(Gs).
Glorious. Perhaps not very practical, but glorious.
Building a proof tree
When our interpreter gives an answer it doesn’t provide any indication as to why that answer was produced. Perhaps the answer is in fact wrong and we want to localize the part of the code that is responsible for the error. The first step in this process is to build a proof tree. A proof tree for a goal 
It might sound like a complex task, but it’s really not. All we need is to extend the 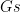
prove(G, T) :-
prove1([G], T).
prove1([], true).
prove1([G|Gs], ((G :- T1), T2)) :-
rule(G, B),
prove1(B, T1),
prove1(Gs, T2).
And when called with ![G = append([a,b], [c,d], Xs)](https://s0.wp.com/latex.php?latex=G+%3D+append%28%5Ba%2Cb%5D%2C+%5Bc%2Cd%5D%2C+Xs%29&bg=FFFFFF&fg=000&s=0&c=20201002)
?- interpreter::prove(append([a,b], [c,d], Xs), T). Xs = [a, b, c, d], T = ((append([a, b], [c, d], [a, b, c, d]):- (append([b], [c, d], [b, c, d]):- (append([], [c, d], [c, d]):-true), true), true), true)
NB: this tree has a lot of redundant
Summary
We’re now able to build proof trees. In the next entry we’re going to use them to localize errors in logic programs.
For a good discussion of meta-interpreters in Prolog the reader should turn to The Craft of Prolog by Richard O’Keefe. This post was just the tip of the iceberg. Another interesting subject is to experiment with different search rules, and for this I shamelessly promote my own bachelor’s thesis which is available at http://www.diva-portal.org/smash/record.jsf?searchId=1&pid=diva2:325247.
Source code
The source code is available at https://gist.github.com/1330321.
