

Introduction
What do you then when (1) Christmas is rapidly approaching, (2) a conference deadline is looming, (3) you will very soon have a bunch of exams and homework assignments to grade. Naturally, rather than tackling these issues head on you instead decide to let an AI attempt to solve an old exam in a logic programming course and then painstakingly grade the output as if it was a serious attempt.
The background is as follows: I was curious as to whether the recently released chatbot ChatGPT lived up to the hype and decided to test how well it would perform on a logic programming exam (where there are likely few exact answers available in its dataset). Spoiler: it did not go so well but still performed much better than what I initially thought, and the most impressive aspect is that I could essentially just copy and paste questions from a PDF without carefully reformulating them to make them understandable.
NB: I promise that this is not going to be one of those posts where I in the end reveal that it was actually written by the AI! Without further ado, the results were as follows.
The Exam
Question 1
Determine which of the following pairs of terms are unifiable, and provide a most general unifier (mgu) in case there is one.
a) p(X,Y,f(a)) p(Y,f(Z),f(X))
b) p(X,f(X,Y)) p(f(Y,Z),Z)
c) p(Y,f(X),Z) p(X,f(a),f(Y))
d) [Y,Z|Y] [X,a,a]
Answer
Unification is the process of finding a substitution that makes two terms syntactically equal. Two terms are unifiable if they can be made equal by substitution. Here are the pairs of terms and whether they are unifiable:
a) p(X,Y,f(a)) p(Y,f(Z),f(X))
These two terms are unifiable, because the variables and function symbols are the same. We can unify them by substituting X for Y and Z for a, resulting in the most general unifier (mgu) p(X,X,f(Z)).
b) p(X,f(X,Y)) p(f(Y,Z),Z)
These two terms are not unifiable, because the second argument of the first term is f(X,Y), but the second argument of the second term is Z. The two arguments do not have the same structure, so they cannot be made equal by substitution.
c) p(Y,f(X),Z) p(X,f(a),f(Y))
These two terms are unifiable, because the variables and function symbols are the same. We can unify them by substituting Y for X and Z for f(Y), resulting in the mgu p(Y,f(X),f(Y)).
d) [Y,Z|Y] [X,a,a]
These two terms are not unifiable, because the first term is a list with three elements, but the second term is a list with four elements. The two terms do not have the same structure, so they cannot be made equal by substitution.
Comments
1a is plain wrong, 1b is not unifiable due to occurs check, the stated reason is non-sensical. However, 1c is correct, except that p(X,X,f(Z)) is not an MGU, in fact, it’s just a term, not a unifier. 1d is quite clearly wrong since the second term is a list with three elements, not four. If I did not know that I was grading an AI generated answer I would be very confused – how could one miscalculate so badly?
Score: 1 credit.
Question 2
Give a simple example of a program and a query for which the results given by Prolog are different from those described by the theory (SLD-resolution). The difference should be finite failure in one case, and success in the other one (under the same selection rule).
A simple example of a program and a query for which Prolog and SLD-resolution give different results is the following:
Program:
p(a).
p(b).
q(X) :- p(X), not r(X).
r(b).Query:
?- q(X).
In this case, Prolog would return X = a and then stop, because it only returns one solution for a query and it uses a depth-first search strategy. In contrast, SLD-resolution would return X = a and then X = b, because it is a complete inference system and it uses a breadth-first search strategy. This difference in search strategy leads to a difference in the results: Prolog fails to find the solution X = b, while SLD-resolution finds it.
Comments
There are several wrong claims here. First, the question uses the term SLD-resolution, which means that it is only applicable to definite logic programs without negation, so to correctly answer the question one should not use a program which contains negation. Second, SLD-resolution is a theoretical notion which does not presume any specific search strategy. Third, SLDNF-resolution with a complete search strategy would not give the answer X = b for the query q(X) since it is clearly false. So, put together, not an impressive answer, but I would not be surprised if one could get an acceptable answer by either tweaking the question or querying it multiple times.
Score: 0 credits.
Question 3
Assume that we are working with lists of natural numbers. Define the following predicates as CLP(N) programs (where N is the standard interpretation over the natural numbers containing the usual arithmetical operations (+,·,−,/), and relations (=, <, ≤, >, ≥)).
(a) even sum/1 which is true if the sum of the input list is even.
Hint: use a simple recursive strategy for checking if a number is even.
(b) sum constraint/2 which is true if the first argument is a list [n1,…,nk] of numbers, the second argument a number c, and for any ni, nj (i ̸= j) we have that ni + nj ≤ c.
Except for arithmetical constraints your program should be a definite clause program. Hence, negation, ( -> ; ), and other Prolog built-in predicates (e.g., list processing predicates) should not be used.
Answer
Here are the CLP(N) programs for the predicates even_sum/1 and sum_constraint/2:
(a) even_sum/1:
even_sum([]).
even_sum([N|Ns]) :- N #= 0 #<=> B, even_sum(Ns), B #= 1.This program defines the even_sum/1 predicate, which is true if the sum of the input list is even. The program uses a simple recursive strategy for checking if a number is even by using the constraint N #= 0 #<=> B, which is true if N is equal to 0 and B is 1, or if N is not equal to 0 and B is 0. The constraint B #= 1 ensures that the number of elements in the list that are equal to 0 is even.
(b) sum_constraint/2:
sum_constraint([], _).
sum_constraint([N|Ns], C) :-sum_constraint(Ns, C),N + N #=< C.
This program defines the sum_constraint/2 predicate, which is true if the first argument is a list of numbers, the second argument is a number C, and for any numbers ni and nj (i != j) in the list, we have that ni + nj <= C. The program uses a simple recursive strategy for checking the sum constraint by using the constraint N + N #=< C, which is true if the sum of any two numbers in the list is less than or equal to C.
Comments
Initially, I was impressed that it actually used constraints. However, it is not close to being correct. The first program is weird. It uses reification to check whether N is equal to 0 or not via B, computes the solution recursively, and then constrains B to be 1, i.e., N should be 0. The second program does not work either: it just checks whether N + N is smaller than C for every number N in the list, which is a much simpler task. Overall, not close to an actual solution, but it seems likely that we could get a solution to the first task by dropping constraints and just using standard Prolog arithmetic since the dataset is larger in that case.
Score: 0 credits.
Question 4
Assume that we represent a direct graph as a collection of edge/2 facts. Write a logic program defining predicates
- vertex/1 which is true if its argument is a vertex in the graph (as described above),
- hamiltonian circuit/0 which is true if the graph (as described above) contains a cycle which visits each vertex in the graph exactly once (a cycle in a graph is a path which begins and ends in the same node).
Hint: hamiltonian circuit/0 should not be defined recursively. Instead, define an auxilliary predicate path(X,Y,Vs) which is true if the graph contains a path from X to Y which visits each node in the list of vertices Vs exactly once. To obtain a list of all vertices in the graph you are allowed to use the following predicate definition.
vertices(Vs) :- setof(V, vertex(V), Vs).
Your program should be a definite clause program. Negation, (->;), arithmetic, and other Prolog built-in predicates (e.g., list processing predicates) should not be used, but you are as usual allowed to define auxilliary predicates if they simplify the task.
Answer
Here is a logic program defining the predicates vertex/1 and hamiltonian_circuit/0:
% vertex/1 is true if its argument is a vertex in the graph.
vertex(V) :- edge(V, ).
vertex(V) :- edge(, V).
% path/3 is true if the graph contains a path from X to Y %which visits
% each node in the list of vertices Vs exactly once.
path(X, Y, [X, Y]) :- edge(X, Y).
path(X, Y, [X|Vs]) :-
edge(X, Z),
\+ member(Z, Vs),
path(Z, Y, Vs).
% hamiltonian_circuit/0 is true if the graph contains a cycle which
% visits each vertex in the graph exactly once.
hamiltonian_circuit :-
vertices(Vs),
path(X, X, Vs),
\+ (member(V, Vs), \+ path(X, V, Vs)).
% vertices/1 is true if its argument is a list of all vertices in the graph.
vertices(Vs) :- setof(V, vertex(V), Vs).
The vertex/1 predicate is defined using two clauses: one for a vertex V that is the first argument of an edge/2 fact, and one for a vertex V that is the second argument of an edge/2 fact.The hamiltonian_circuit/0 predicate is defined using three clauses. The first clause generates a list of all vertices in the graph using the vertices/1 predicate. The second clause checks if the graph contains a path from a vertex X to itself that visits each vertex in the list exactly once using the path/3 predicate. The third clause checks if the graph contains a path from the starting vertex X to every other vertex in the list using the path/3 predicate.
The vertices/1 predicate is defined using the setof/3 built-in predicate to generate a list of all vertices in the graph. This predicate uses the vertex/1 predicate as a goal in the setof/3 call, which allows it to collect all vertices in the graph without using negation or other built-in predicates.
Comments
It managed to get the graph representation and the definition of vertex/1 right, and introduced vertices/1 as an auxilliary predicate as suggested – not bad! The predicate defining a hamiltonian circuit is not close to being correct but, on the bright side, manages to define path/3 as an auxilliary predicate. As usual, instructions to ignore certain features of Prolog (e.g., negation) are ignored. But more severely, the path/3 predicate is wrong and uses the third argument in a (to put it mildly) bizzare way, and the nested usage of negation in hamiltonian_circuit/0 puts me in a cranky mood. However, if we fix path/3 so that it only builds up the path, remove the negation in hamiltonian_circuit which accomplishes nothing, and add a condition for checking whether the obtained path contains every vertex exactly once, then we are not far away from a solution (although there’s a simpler solution). So, essentially, if we rewrite the entire program we obtain a poor solution.
Score: 1 credit for vertex/1.
Question 5
Consider the following definite program P :
p(f(X),g(X)).
q(a).
q(Z) ← p(Z, Z). r(g(Z)).
r(Z) ← r(Y ), p(Z, g(Y)).
Answer the following questions:
(a) Assume that the vocabulary A contains one constant a and two unary function symbols f and g. What is the Herbrand universe UA corresponding to A?
(b) Find the least Herbrand model MP of the program.
(c) Give an example of a ground atom (with predicate symbol r) which is a logical consequence of P.
(d) Give an example of a ground atom (with predicate symbol r) which is not a logical consequence of P.
(e) Does there exist a non-ground atom (whose predicate symbol is q or r) which is a logical consequence of P? Your atom should not be an instance of a unary clause (fact) in the program.
Answer
(a) The Herbrand universe UA corresponding to the vocabulary A is the set of all ground terms that can be constructed using the constant a and the unary function symbols f and g. This set is:
{a, f(a), g(a), f(f(a)), g(f(a)), f(g(a)), g(g(a)), f(f(f(a))), g(f(f(a))), …}(b) The least Herbrand model MP of the program is the set of all ground atoms that are true in all interpretations over the Herbrand universe UA. This set is:
{p(f(a), g(a)), q(a), r(g(a)), r(g(g(a))), r(g(g(g(a)))), …}
(c) An example of a ground atom that is a logical consequence of the program is r(g(a)), because this atom can be derived using the second clause of the r/1 predicate. This atom can be derived by applying the substitution Z/g(a), Y/a to the clause r(Z) :- r(Y), p(Z, g(Y)).(d) An example of a ground atom that is not a logical consequence of the program is r(f(a)), because this atom cannot be derived using any of the clauses in the program. This is because the only clause that involves the r/1 predicate requires that its argument be of the form g(Z), but f(a) does not match this form.
(e) There does not exist a non-ground atom (whose predicate symbol is q or r) which is a logical consequence of the program. This is because all of the clauses in the program are unary facts, which means that they only apply to ground atoms. Non-ground atoms cannot be derived using these clauses, because they require substitution to be applied to the variables in the atoms.
Comments
1a is genuinely impressive. 1b is dead wrong but it is at least an Herbrand interpretation. 1c is correct, but 1d and 1e are wrong.
Score: 1 credit.
Question 6
For a chosen query Q and a chosen subset P6 ⊆ P of the previous program, construct two SLD-trees – one finite and one infinite.
Let the chosen query be r(g(a)) and the chosen subset of the program be P6 = {p(f(X),g(X)), q(a), r(g(Z)) :- r(Y), p(g(Z), g(Y))}.
To construct the finite SLD-tree, we can start by unifying the query with the first clause of the r/1 predicate in the program subset. This results in the goal r(Y), p(g(a), g(Y)) and the substitution Z/g(a), Y/Y. We can then apply the second clause of the r/1 predicate to this goal, resulting in the goal r(Y) and the substitution Z/g(a), Y/Y, Y/Y. Because there are no more clauses in the program subset that match this goal, the SLD-tree terminates and is finite.
To construct the infinite SLD-tree, we can again start by unifying the query with the first clause of the r/1 predicate in the program subset. This results in the goal r(Y), p(g(a), g(Y)) and the substitution Z/g(a), Y/Y. We can then apply the second clause of the r/1 predicate to this goal, resulting in the goal r(Y) and the substitution Z/g(a), Y/Y, Y/Y. However, because the r/1 predicate appears in the body of its own clause, we can apply the clause again to this new goal, resulting in the goal r(Y) and the substitution Z/g(a), Y/Y, Y/Y, Y/Y. This process can be repeated indefinitely, resulting in an infinite SLD-tree.
Comments
Yet another answer which seems reasonable at a first glance but which turns out to be utter nonsense. First, the set is not actually a subset of the program. Second, it is argued that the SLD-tree is both finite and infinite, without realizing that one should produce two different trees under two distinct computation rules.
Score: 0 credits.
Question 7
Consider the Prolog program PREFIX:
p([], L).
p([H|T],[H|L]) :- p(T,L).
(a) Is PREFIX complete with respect to the specification {p([t1,…,tm],[s1,…,sm])|m≥1,t1,…,tm,s1,…,sm ∈UA}?
A brief explanation is sufficient here, no formal proof is required.
(b) Prove that PREFIX is correct with respect to the specification
{p(u, t) | u, t ∈ UA, if u, t are lists then len(u) ≤ len(t)} (where len(l) is the length of a list l, e.g. len([t1, . . . , tn]) = n).
Answer
(a) The program PREFIX is not complete with respect to the specification {p([t1,…,tm],[s1,…,sm])|m≥1,t1,…,tm,s1,…,sm ∈UA}. This is because the program only defines the p/2 predicate for the case where the first argument is an empty list or a non-empty list with a head and a tail, but it does not define the predicate for other cases. For example, the program does not define the p/2 predicate for the case where the first argument is a non-empty list without a tail, such as p([a], [a,b,c]).
(b) To prove that PREFIX is correct with respect to the specification {p(u, t) | u, t ∈ UA, if u, t are lists then len(u) ≤ len(t)}, we must show that for any ground terms u and t that satisfy the condition len(u) ≤ len(t), the goal p(u, t) is entailed by the program.
We can do this by proving that the p/2 predicate defined in the program is correct for any ground terms u and t that satisfy the condition len(u) ≤ len(t). If u is an empty list, then the first clause of the p/2 predicate is applicable and the goal p(u, t) is entailed. If u is a non-empty list with a head H and a tail T, then the second clause of the p/2 predicate is applicable, and the goal p(u, t) can be derived by applying the goal p(T, L) and the substitution L/[H|L] to the clause.
To complete the proof, we need to show that the goal p(T, L) is entailed for any list T and L such that len(T) ≤ len(L). If T is an empty list, then the first clause of the p/2 predicate is applicable and the goal p(T, L) is entailed. If T is a non-empty list with a head H and a tail T’, then the second clause of the p/2 predicate is applicable, and the goal p(T, L) can be derived by applying the goal p(T’, L’) and the substitution L’/[H|L’] to the clause. Because len(T) = len(T’) + 1 and len(L) = len(L’) + 1, it follows that len(T) ≤ len(L) if and len(T’) ≤ len(L’), which means that the goal p(T’, L’) is entailed by the program.
By induction, we can conclude that the goal p(T, L) is entailed for any list T and L such that len(T) ≤ len(L), which means that the p/2 predicate defined in the program is correct with respect to the specification. This completes the proof that PREFIX is correct with respect to the specification.
Comments
This is not an easy question and I did not expect a correct answer. 7a is indeed a brief explanation and not a formal proof, so it looks plausible even though all of the claims are wrong. 7b is actually not that far away from a working proof even though the assumptions are not stated correctly. What we have to prove in the inductive case is that if l and t are lists where len(l) =< len(t) then [x|l] and [x|t] are lists where len([x|l]) =< len([x|t]). What we get is an incorrect word salad but which would not be that hard to fix into an actual proof.
Score: 1 credit for an attempt at an inductive proof and reasoning about the specification.
Question 8
Write a definite clause grammar (DCG) which recognizes the language {abb, aabbb, aaabbbb, …}.
Show that [a,a,b,b,b] is a member of the language by either (1) sketching a derivation of your DCG, or (2) translating the grammar to Prolog and providing a successful SLD-derivation.
Your DCG is not allowed to use the {} construct for evaluating Prolog code.
Solution
Here is a DCG that recognizes the language {abb, aabbb, aaabbbb, …}:
Copy code
s –> a, s, b.
s –> a, b.
To show that [a,a,b,b,b] is a member of the language, we can sketch a derivation using the DCG:s
–> a, s, b
–> a, a, b, s, b
–> a, a, b, b
Alternatively, we can translate the DCG to Prolog and provide a successful SLD-derivation. Here is the translation:
s(X) :- a(X, Y), s(Y, Z), b(Z).
s(X) :- a(X, Y), b(Y).
And here is a successful SLD-derivation for [a,a,b,b,b]:
- s([a,a,b,b,b])
- a([a,a,b,b,b], [a,b,b,b])
- b([a,b,b,b])
- s([a,b,b,b])
- a([a,b,b,b], [b,b,b])
- b([b,b,b])
Note that we can also use the DCG to generate strings in the language. For example, to generate the string aaabbbb, we can use the following derivation:s
–> a, s, b
–> a, a, b, s, b
–> a, a, b, b, s, b
–> a, a, b, b, b
Comments
This did not go well, the grammar is wrong and not close to being correct. I made a handful of attempts to change the formulation of the question but without success.
Score: 0 credits.
Question 9
Consider the general logic program P9:
p(X, Y ) ← m(X, Y ).
p(X, Y ) ← ¬m(X, Y ).
m(H, [H|L]).
m(E, [H|L]) ← m(E, L).
Answer the following questions:
(a) Draw SLDNF-trees for the queries p(a, b) and p(a, Y). Make it clear which trees are finitely failed, which leaves are floundered, which branches are successful and what their answers are. If a tree has many answers, make at least two of them explicit.
(b) Construct the completion Comp(P9) of the program (except for the equality axioms CET). Explain whether ∀Y : p(a, Y ) is a logical consequence of Comp(P9) (a high-level explanation is sufficient).
Solution
(a) Here are the SLDNF-trees for the queries p(a, b) and p(a, Y):
Query: p(a, b)
p(a, b)
/ \
m(a, [a|b]) ¬m(a, [a|b])
|
| X = [a|b]
m(a, X)
/ \
X = [H|L], H = a X = [H|L], ¬H = a
L = b m(a, L)
/ \
X = [H|L], H = a X = [H|L], ¬H = a
L = [] m(a, L)
|
| X = []
false
In this tree, the left branch is successful, since m(a, [a|b]) is true. The right branch is finitely failed, since it leads to the floundered subgoal m(a, []).Query: p(a, Y)
p(a, Y)
/ \
m(a, [a|Y]) ¬m(a, [a|Y])
|
| X = [a|Y]
m(a, X)
/ \
X = [H|L], H = a X = [H|L], ¬H = a
L = Y m(a, L)
/ \
X = [H|L], H = a X = [H|L], ¬H = a
L = [] m(a, L)
|
| X = []
false
In this tree, both branches are successful. The left branch leads to the answer Y = [], and the right branch leads to the answer Y = [a|Y]. This tree has two answers, but it could have many more if we continued to explore the right branch.(b) The completion of P9 is the set of all ground instances of clauses that can be derived from P9 using the SLDNF proof procedure. Some examples of clauses that can be derived from P9 are:
m(a, [a|L]) :- m(a, L).
m(a, [H|L]) :- H = a, L = [].
p(a, []) :- ¬m(a, []).
It is not a logical consequence of Comp(P9) that ∀Y : p(a, Y) is true, because there are ground instances of p(a, Y) that are not entailed by Comp(P9). For example, p(a, [b]) is not entailed by Comp(P9), since it is not possible to prove m(a, [b]) using the rules in P9.
Comments
On the bright, side, we got two beautifully drawn ASCII trees (which I’ve completely butchered in the WordPress translation). However, almost nothing is correct so I can’t hand out any credits here.
Score: 0 credits.
Question 10
Consider the general logic program P10:
innocent(X) ← ¬guilty(X).
guilty(X) ← ¬innocent(X).
guilty(X) ← crime(X, Y).
crime (b, theft).
The Herbrand universe consists of the constants a, b, and theft. Answer the following questions:
(a) Find an Herbrand interpretation of the program which is not a model.
(b) Find an Herbrand model which is not stable.
(c) Find a stable model of the program.
Solution
(a) Here is an Herbrand interpretation of the program that is not a model:
innocent(a) is true.
innocent(b) is false.
guilty(a) is true.
guilty(b) is true.
crime(b, theft) is true.
This interpretation is not a model, because it violates the first rule in the program. The first rule states that if X is not guilty, then X is innocent. In this interpretation, guilty(a) is true, but innocent(a) is also true, which violates the rule.(b) Here is an Herbrand model of the program that is not stable:
innocent(a) is true.
innocent(b) is false.
guilty(a) is false.
guilty(b) is true.
crime(b, theft) is true.
This model is not stable, because we can derive a contradiction from the rules in the program. Specifically, we can use the second and third rules to show that guilty(a) is both true and false, which is a contradiction.(c) Here is a stable model of the program:
innocent(a) is false.
innocent(b) is false.
guilty(a) is true.
guilty(b) is true.
crime(b, theft) is true.
This model is stable, because it does not violate any of the rules in the program, and it does not contain any contradictions. It satisfies the first rule, because guilty(a) is true and innocent(a) is false. It satisfies the second rule, because guilty(a) is true and innocent(a) is false. It satisfies the third rule, because guilty(b) is true and crime(b, theft) is true. And it satisfies the fourth rule, because crime(b, theft) is true.
Comments
It successfully reasons about Herbrand intepretations of the program but apart from that everything is wrong.
Score: 0 credits.
Summary
Altogether the AI managed to scrape together 4 credits which is far from a passing grade. It misunderstood all basic concepts but still managed compose answers which, at a passing glance, looked reasonable, which is no small feat. If this had been an actual student submission then my largest concern would be the discrepancy between the generally well-presented solutions and the very limited understanding. It would not be the worst exam that I have ever graded but would certainly raise some eyebrows. It seems likely that the AI would have scored much higher for other types of exams, e.g., an introductory course in programming using a more mainstream programming language, where there is more available data. Although my own course is not affected since students do not have Internet access during the exam I am probably carefully going to check homework assignments from now on to make sure that they are not trivially solvable.
It is still unclear to me to which extent such tools are useful in university education. When is it useful to generate an answer which is likely incorrect, and which may or may not be possible to patch to a correct answer, rather than writing a solution from scratch?

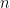 requires a nested term of depth
requires a nested term of depth 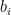 is a bit. For example, byte(1,0,0,1,0,0,0,1) would represent the byte 10010001. Since bytes consists of bits, let’s begin by writing a predicate which adds two bits, before we worry about solving the larger problem, and once we know how to add two bytes, we’ll worry about integer and floating point addition. But how can we accomplish this without using any built-in predicates? I’m quite convinced that if this question was asked during a programming interview then not that many would obtain an acceptable solution, but it’s actually very simple: just hardwire the required information. Thus, if the two given bits are 0, the third bit should be 0, and if one of them is 1 but the other one is 0, the result should be 1. In other programming languages we would encode this with a handful of if-statements, and in Prolog the easiest solution is to represent each such case by a fact.
is a bit. For example, byte(1,0,0,1,0,0,0,1) would represent the byte 10010001. Since bytes consists of bits, let’s begin by writing a predicate which adds two bits, before we worry about solving the larger problem, and once we know how to add two bytes, we’ll worry about integer and floating point addition. But how can we accomplish this without using any built-in predicates? I’m quite convinced that if this question was asked during a programming interview then not that many would obtain an acceptable solution, but it’s actually very simple: just hardwire the required information. Thus, if the two given bits are 0, the third bit should be 0, and if one of them is 1 but the other one is 0, the result should be 1. In other programming languages we would encode this with a handful of if-statements, and in Prolog the easiest solution is to represent each such case by a fact.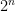 and store such numbers by encoding the exponent
and store such numbers by encoding the exponent  in a fixed number of bits so that a number is represented by a term
in a fixed number of bits so that a number is represented by a term 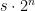 . The point of such a representation is that if we, say, add two large numbers, then we might not have enough bits to accurately add the significands of the two numbers, but we can get reasonable close by making sure that the exponents and the most significant bits in the significands are added correctly. These days floating point arithmetic is typically taken care of with dedicated hardware, but in the heydays of BASIC-80 floating point operations were quite often implemented as a software layer in the interpreter.
. The point of such a representation is that if we, say, add two large numbers, then we might not have enough bits to accurately add the significands of the two numbers, but we can get reasonable close by making sure that the exponents and the most significant bits in the significands are added correctly. These days floating point arithmetic is typically taken care of with dedicated hardware, but in the heydays of BASIC-80 floating point operations were quite often implemented as a software layer in the interpreter.
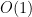 read/write operations unless we enforce a (small) constant limit on the allowed number of elements. For example, assume that we only allow 4 elements in each array. Then we could implement a set/4 operation as follows.
read/write operations unless we enforce a (small) constant limit on the allowed number of elements. For example, assume that we only allow 4 elements in each array. Then we could implement a set/4 operation as follows.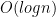 read and write operations instead, provided by e.g. library(assoc). A list would in all likelihood also be an acceptable choice but wouldn’t really be that much easier to implement. But let’s now turn to the implementation. Arrays are defined and used in the following way.
read and write operations instead, provided by e.g. library(assoc). A list would in all likelihood also be an acceptable choice but wouldn’t really be that much easier to implement. But let’s now turn to the implementation. Arrays are defined and used in the following way.
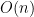 time, which is quite bad since its something that the interpreter is going to do in each iteration. While I’m not concerned over low level efficiency, there’s no point in using suboptimal data structures when a more reasonable choice exists. But if I’m so concerned about data structures, why don’t I use an array indexed by line numbers, so that accessing a statement at a given line takes constant time? Well, mainly because we in that case first would have to normalize the line numbers, and since working with “flat” terms to simulate arrays is typically not a great experience in Prolog (it would, for example, be cumbersome if we want to extend the interpreter to support line editing). Also,
time, which is quite bad since its something that the interpreter is going to do in each iteration. While I’m not concerned over low level efficiency, there’s no point in using suboptimal data structures when a more reasonable choice exists. But if I’m so concerned about data structures, why don’t I use an array indexed by line numbers, so that accessing a statement at a given line takes constant time? Well, mainly because we in that case first would have to normalize the line numbers, and since working with “flat” terms to simulate arrays is typically not a great experience in Prolog (it would, for example, be cumbersome if we want to extend the interpreter to support line editing). Also, 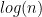 time is still great : if we have a BASIC program with 1000 lines then we’re going to find the statement associated with a given line in roughly 10 steps, and if we double the program size to 2000 lines then the cost only increases to 11 steps, and so on. However, if there’s a reader with a huge BASIC program which he/she for some reason can’t run in any other interpreter, and for which the tree representation turns out to be too slow, then I promise to change the representation!
time is still great : if we have a BASIC program with 1000 lines then we’re going to find the statement associated with a given line in roughly 10 steps, and if we double the program size to 2000 lines then the cost only increases to 11 steps, and so on. However, if there’s a reader with a huge BASIC program which he/she for some reason can’t run in any other interpreter, and for which the tree representation turns out to be too slow, then I promise to change the representation!

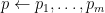 , where
, where 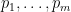 is treated as a conjunction. Implications of this form should be interpreted as:
is treated as a conjunction. Implications of this form should be interpreted as:  is true if
is true if 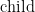 relation between two individuals, so that
relation between two individuals, so that 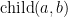 holds if
holds if 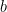 is a child to
is a child to  , then we could define the
, then we could define the 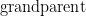 relationship between two individuals as:
relationship between two individuals as: 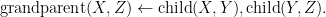 By convention, variables are written with uppercase letters, and are universally quantified when they appear in the head of a rule, and existentially quantified otherwise. Hence, the previous rule should be read as:
By convention, variables are written with uppercase letters, and are universally quantified when they appear in the head of a rule, and existentially quantified otherwise. Hence, the previous rule should be read as:  is a grandparent of
is a grandparent of 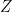 if there exists an individual
if there exists an individual 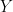 such that
such that  . The meaning of a logic program is the set of all logical consequences of the program. Hence, we encode our problems as logic, and solutions correspond to logical consequences.
. The meaning of a logic program is the set of all logical consequences of the program. Hence, we encode our problems as logic, and solutions correspond to logical consequences.  before returning control.
before returning control. are written as
are written as 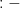 . For example, assume that we want to define a relation which we can use to check whether an element occurs in a list (Prolog has built-in syntax for lists where an expression of the form
. For example, assume that we want to define a relation which we can use to check whether an element occurs in a list (Prolog has built-in syntax for lists where an expression of the form ![[X|Rest]](https://s0.wp.com/latex.php?latex=%5BX%7CRest%5D&bg=FFFFFF&fg=000&s=0&c=20201002) means that
means that 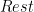 ). The usual definition of this program is:
). The usual definition of this program is:![[Y|Rest]](https://s0.wp.com/latex.php?latex=%5BY%7CRest%5D&bg=FFFFFF&fg=000&s=0&c=20201002) , regardless of what
, regardless of what ![\mathrm{member}(X, [X|Rest])](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bmember%7D%28X%2C+%5BX%7CRest%5D%29&bg=FFFFFF&fg=000&s=0&c=20201002) , rather than the more cumbersome:
, rather than the more cumbersome: ![\mathrm{member}(X, [Y|Rest]) :- X = Y](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bmember%7D%28X%2C+%5BY%7CRest%5D%29+%3A-+X+%3D+Y&bg=FFFFFF&fg=000&s=0&c=20201002) . In the recursive case we remove the first element from the list, call it
. In the recursive case we remove the first element from the list, call it  and a goal query
and a goal query  . Sterling and Shapiro cites three possible bugs in The Art of Prolog:
. Sterling and Shapiro cites three possible bugs in The Art of Prolog: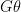 . (incorrectness)
. (incorrectness)
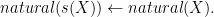
 or the set
or the set  . Notice the subtle difference. The latter model is simpler in the sense that it doesn’t take us outside the domain of the textual representation of the program itself. Such models are known as Herbrand models. Could we be so lucky that Herbrand models are the only kind of models that we need to pay attention to? This is indeed the case. If a logic program has a model then it also has a Herbrand model. But we still need to pick and choose between the infinitely many Herbrand models. The intuition is that a model of a logic program shouldn’t say more than it have to. Hence we choose the smallest Herbrand model as the meaning of a logic program. Or, put more succinct, the intersection of all Herbrand models. For a logic program
. Notice the subtle difference. The latter model is simpler in the sense that it doesn’t take us outside the domain of the textual representation of the program itself. Such models are known as Herbrand models. Could we be so lucky that Herbrand models are the only kind of models that we need to pay attention to? This is indeed the case. If a logic program has a model then it also has a Herbrand model. But we still need to pick and choose between the infinitely many Herbrand models. The intuition is that a model of a logic program shouldn’t say more than it have to. Hence we choose the smallest Herbrand model as the meaning of a logic program. Or, put more succinct, the intersection of all Herbrand models. For a logic program 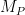 denote the smallest Herbrand model of
denote the smallest Herbrand model of  of a logic program
of a logic program 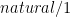 , the intended meaning is nothing else than the actual meaning, i.e. the set
, the intended meaning is nothing else than the actual meaning, i.e. the set 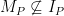 .
.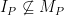 .
.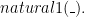
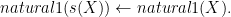
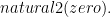
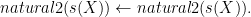
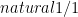 is incorrect since the base clause is too inclusive.
is incorrect since the base clause is too inclusive.  is not a member of
is not a member of  is insufficient since it’s equivalent to just
is insufficient since it’s equivalent to just 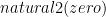 .
.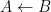 is false iff
is false iff  is true and
is true and 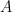 is false. The purpose of the algorithm is to traverse the proof tree and find such a clause. With this in mind we can at least write the top-level predicate:
is false. The purpose of the algorithm is to traverse the proof tree and find such a clause. With this in mind we can at least write the top-level predicate: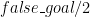 ? The tree is of the form
? The tree is of the form  , where the first argument is the conjunction of nodes and the second argument is the false clause (if it exists).
, where the first argument is the conjunction of nodes and the second argument is the false clause (if it exists). . The second argument is
. The second argument is 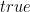 if
if  if it’s false. How can we know this? This is where the programmer’s intended model enters the picture. For now, we’re just going to use her/him as an oracle and assume that all choices are correct. The predicate is then trivial to write:
if it’s false. How can we know this? This is where the programmer’s intended model enters the picture. For now, we’re just going to use her/him as an oracle and assume that all choices are correct. The predicate is then trivial to write: we can store these in the same manner. Assume that
we can store these in the same manner. Assume that  , represent it as the fact
, represent it as the fact ![rule(A, [B_1, ..., B_n])](https://s0.wp.com/latex.php?latex=rule%28A%2C+%5BB_1%2C+...%2C+B_n%5D%29&bg=FFFFFF&fg=000&s=0&c=20201002) . If a rule only has the single atom
. If a rule only has the single atom 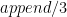 :
: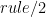 we can rewrite
we can rewrite 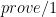 clauses where the single argument is a list of goals. If you’ve never seen a meta-interpreter in Prolog before, you’re probably in for some serious disappointment since the program is so darn simple. So simple that a first reaction might be that it can’t possibly do anything useful. This first impression is wrong, however, since it’s easy to increase the granularity of the interpreter by implementing features instead of borrowing them from the Prolog system.
clauses where the single argument is a list of goals. If you’ve never seen a meta-interpreter in Prolog before, you’re probably in for some serious disappointment since the program is so darn simple. So simple that a first reaction might be that it can’t possibly do anything useful. This first impression is wrong, however, since it’s easy to increase the granularity of the interpreter by implementing features instead of borrowing them from the Prolog system.![[G|Gs]](https://s0.wp.com/latex.php?latex=%5BG%7CGs%5D&bg=FFFFFF&fg=000&s=0&c=20201002) where
where 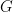 is the first goal that shall be proven. How do we prove
is the first goal that shall be proven. How do we prove  and recursively prove
and recursively prove ![([B_1, ..., B_n|Gs]) \theta](https://s0.wp.com/latex.php?latex=%28%5BB_1%2C+...%2C+B_n%7CGs%5D%29+%5Ctheta&bg=FFFFFF&fg=000&s=0&c=20201002) . In almost any other language this would be considerable work, but since Prolog is a logic programming language we already know how to do unification. Thus we end up with:
. In almost any other language this would be considerable work, but since Prolog is a logic programming language we already know how to do unification. Thus we end up with: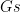 and builds a proof tree from the recursive goals.
and builds a proof tree from the recursive goals.![G = append([a,b], [c,d], Xs)](https://s0.wp.com/latex.php?latex=G+%3D+append%28%5Ba%2Cb%5D%2C+%5Bc%2Cd%5D%2C+Xs%29&bg=FFFFFF&fg=000&s=0&c=20201002) the resulting tree looks like this:
the resulting tree looks like this: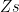 is the list obtained when appending all the elements of
is the list obtained when appending all the elements of 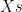 with all the elements of
with all the elements of 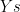 . So when should we use this predicate? When we want to append two lists? No! Upon years of using Prolog I don’t think I’ve used
. So when should we use this predicate? When we want to append two lists? No! Upon years of using Prolog I don’t think I’ve used 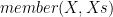 is true if
is true if  with the difference being that we’re looking for a list instead of a single element. Assume that we had the predicate
with the difference being that we’re looking for a list instead of a single element. Assume that we had the predicate  . Then sublist could be solved as:
. Then sublist could be solved as:![Xs = [a,b]](https://s0.wp.com/latex.php?latex=Xs+%3D+%5Ba%2Cb%5D&bg=FFFFFF&fg=000&s=0&c=20201002) . Then the answer
. Then the answer ![Ys = [b]](https://s0.wp.com/latex.php?latex=Ys+%3D+%5Bb%5D&bg=FFFFFF&fg=000&s=0&c=20201002) can be found by first binding
can be found by first binding ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=FFFFFF&fg=000&s=0&c=20201002) and then
and then ![[b]](https://s0.wp.com/latex.php?latex=%5Bb%5D&bg=FFFFFF&fg=000&s=0&c=20201002) of this list. Or it can be found by binding
of this list. Or it can be found by binding  ,
, 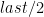 and other basic list processing predicates can be implemented in essentially the same manner. As a last example we’re going to implement
and other basic list processing predicates can be implemented in essentially the same manner. As a last example we’re going to implement 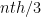 with
with  .
.  is true if
is true if 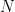 :th member of
:th member of  . One observation is enough to give us a solution:
. One observation is enough to give us a solution: 